无论我们喜欢做什么,在某种程度上肯定是会有回报的(例如,多巴胺促进的嗅觉联想学习,对得失判断的神经表征[1,2,3,4,5]) ,这与强化学习的框架相一致(图31.1; 元强化学习[6])。目前认为纹状体的多巴胺并不代表享受回报本身(阿片类受体),而更是对渴望(wanting)这一动机的价值表征,这也是学习过程中会更新迭代的参数(图31.2)[7]。对调控多巴胺的参数变化,决定了是在求不得与怕失去中蹉跎,还是更新奖惩的参数设置,或更开放地探索新目标。
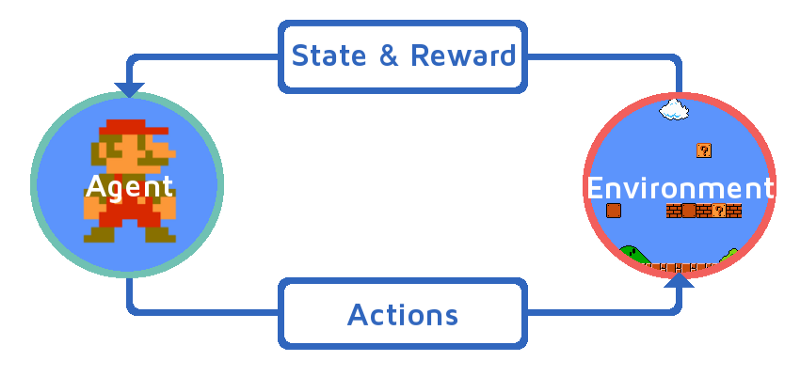
图31.1 强化学习框架示意图。 来源: https://www.freecodecamp.org/news/a-brief-introduction-to-reinforcement-learning-7799af5840db/
我们在第16节讲到的模拟研究结果,从内嗅皮层(LEC、MEC)直接到海马 CA1的单突触通路(图16.1上方,树突已接近细胞体)能够支持统计学习(更新权重),属于对已有连接模式的调用,神经连接越使用越健壮;而来自内嗅皮层、通过齿状回和 CA3到 CA1(图16.1中间拐入,三处的神经元信号都从顶端树突输入[8] ,可通过单个事件学习[9],是更细节的记录。
除了情景记忆,MEC还包含奖励信息(来自中脑腹侧被盖区和黑质区的多巴胺) ,当存在奖励时,更有可能激活学到对应的动作)(图31.2)[10,11,12]。而过往的恐惧记忆也被用于路线规划(图31.3)[11],这里涉及回放(replay)与预放(preplay)的切换。逆序的重放,即从到达目标的位置往之前放,受奖惩大小的调节[13]。我们在第22节提到,有报道记忆回放的方向跟外部输入与海马CA1区theta波的相位有关:内嗅皮层第三层对CA1的单突触输入如果砸在了该区域theta波的波峰上,可能促进逆序的回放(从结果反思过程的强化学习),而海马CA3对CA1的输入在CA1区theta波波谷时到达,促进正向的回放[14],规划路线(或者社交、语言等)。
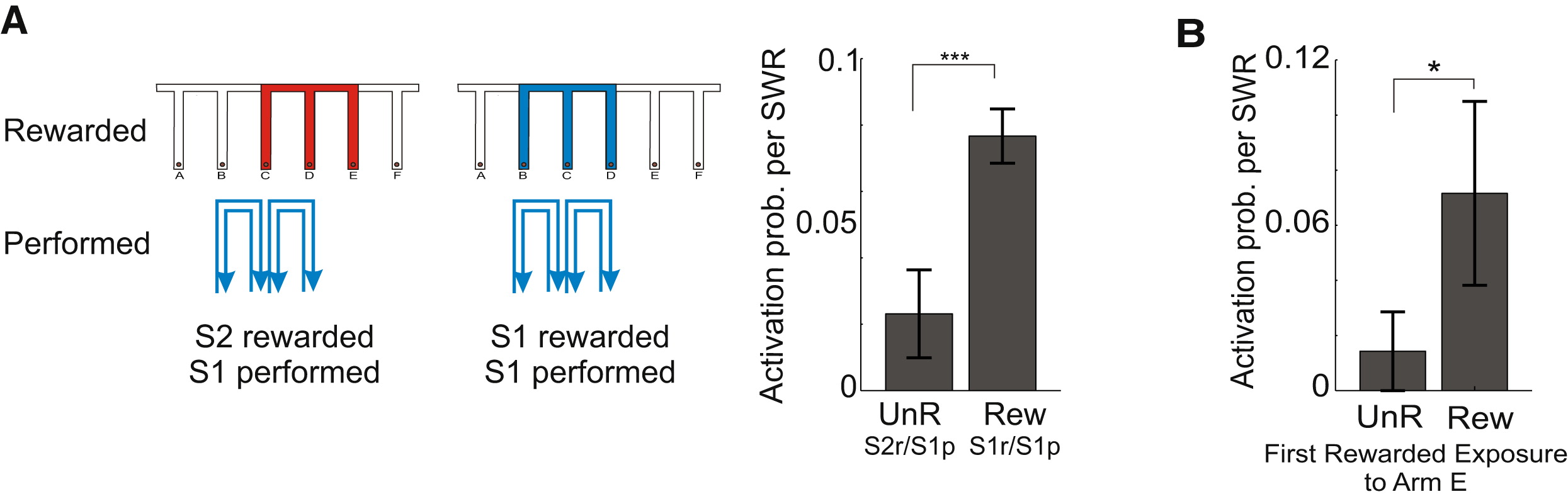
图31.2 大鼠在奖励和未奖励条件下尖波涟漪(SWR)活动的比较。(A)迷宫形状一致,行为S1与奖励错配或匹配,激活尖波涟漪的概率有显著差异。(B)根据子图A左侧经验不预期有奖励,然后在E臂首次获得奖励的尖波涟漪激活。来自[10]
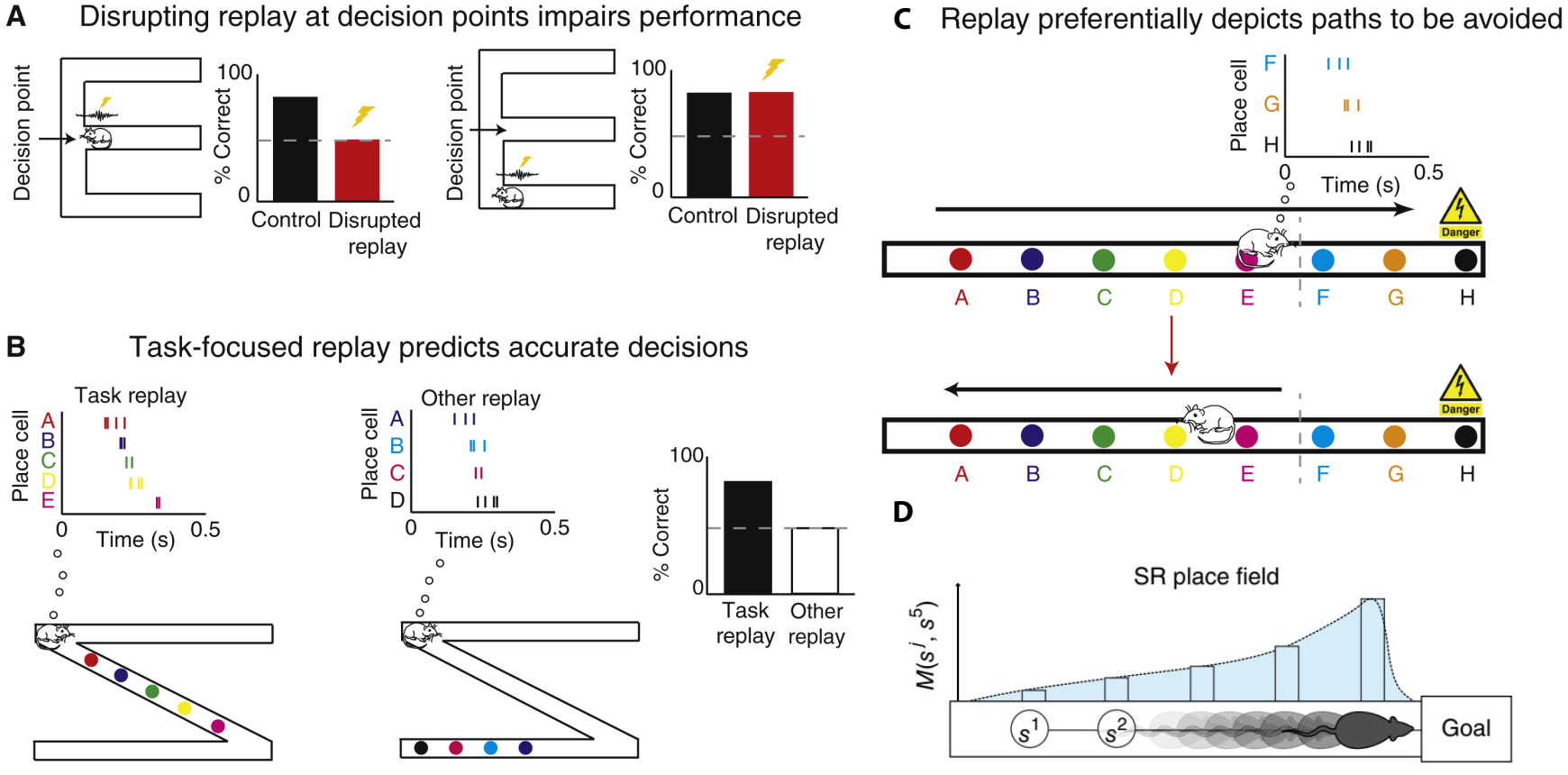
图 31.3 回放或预放规划路径并确定目标。(A)与对照组动物相比,在空间交替任务(“ w 迷宫”)中,在决策时干扰尖波涟漪与表现受损有关(左)。当尖波涟漪在非决策点受到干扰时,决策能力不受影响(右)。(B)在正确和不正确的转弯之前,即z 形跑道的转弯处记录回放是否发生。当回放描述的位置与动物当前的位置一致时(例如,近端位置,左侧) ,老鼠更有可能做出正确的转向(右侧)。然而,如果回放描述的是与当前行为无直接关系的位置(中间) ,那么动物就不太可能做出正确的转弯(右)。(C)在进行了抑制性回避任务(学会将直线跑道末端与脚部电击联系起来)的训练之后,在进入电击区之前的暂停期间重放,优先描绘出通往恐惧区(上方)的路径,并与动物从电击区转身朝相反方向跑(下方)联系起来。(D)单个连续表征的编码单元的位置场向后倾斜,朝向预测单元首选状态的过去状态。A-C来自[11], D来自[12]
不管有没有经过计划,执行以后获得奖惩与否、大小是否符合预期,都涉及参数更新,这也是大脑中不断迭代的对抗生成网络(图27.4)的一部分。首次获得奖励就是一个学习的过程(图31.2B),在回放中得到强化。实验小鼠在按预期获得奖励后,纹状体中释放的多巴胺会抑制乙酰胆碱的释放;而在未得到预期的奖励之后,来自大脑皮层和丘脑的谷氨酸信号则会促进乙酰胆碱的释放,从而改变对奖励与预期行为关系的评估[15]。符合预期的多巴胺释放记录了奖励,而一次未获得的奖励可能带来更多参数的更新[15]。我们在快速眼动睡眠REM章节中也讲到了局部乙酰胆碱释放(图22.2),这在清醒的大脑皮层也是常用的神经递质。腹侧被盖区(VTA)中的谷氨酸神经元释放的谷氨酸能够增强行为[16]。而如果与谷氨酸共同释放了多巴胺,则具有引起厌恶反应的作用[16]。另一项研究显示,VTA多巴胺释放最初既标记了有效行为,还包括了这之前几秒的行为,后续的学习才使得“归因”更准确,可以由近及远包括几步行为的序列[17]。在数字世界中花费过多金钱这一倾向,可能也在于缺乏具象的损失与回报的参考锚点,也缺乏掏钱数钱的过程。
在伏隔核中,D1中型多棘神经元(medium spiny neurons, MSN)负责追踪刺激的重要性(显著性),这包括无论是奖励还是惩罚的刺激;而D2中型多棘神经元则负责检测预期与实际结果之间的差异,即预测误差[18]。这种对权重和误差分别拟合的方式,值得人工智能学习。
对给定目标的追求可能是有代价的。在对果蝇的研究中,饥饿的果蝇还是可以在追寻训练目标时忽略食物和电击风险,这些选项各有多巴胺能神经元表征[19]。雄性果蝇在交配接近成功时,多巴胺抑制了检测危险的视觉神经元;而在交配更早的阶段,这样的危险能够通过5-HT使果蝇及时放弃[20].
通过感知的“显著性”,包括电鱼在内的十种动物,被发现可在探索和利用信息间切换。即随着感知显著性的增加,目标明确的“利用”动作增加,获得丰富信息的“探索”行为减少[21]。我们在树突棘的章节讲到,发育早期较细长的树突棘代表了不确定性,一次强刺激就可以实现贝叶斯学习,后续统计进一步略增加确定性。
相比追求有预期的奖励,环境的新颖性提供了另一种刺激[22,23,26]。我们在睡眠(觉醒)章节提到的下丘泌素/食欲素(hypocretin又称orexin)多肽,在小鼠探索新物件时在MEC中表达量更高,可以通过表达小清蛋白的中间神经元增强gamma波[26]。这体现了下丘脑这一进化上古老区域对MEC空间探索的调控[26]。这种通过快速反应的抑制性中间神经元调控锥体神经元网络的模式也与前文一致。
本书在记忆、视觉、时间、头部朝向等章节讲到,各类刺激信息的记忆存储所包括的神经元细胞本身就有梯度,大部分神经元只是被略微设置了偏好,可能也更易以后再被存入其他信息。在新环境中,适当放松比对的参数(图31.4)可以保证存在过往经历可以作参考,从而在微弱的证据时能匹配旧有经验。也因为如此,成年人很少有需要真正从头学起的场景。如果不够好用,那又是一轮迭代更新(图27.4)。
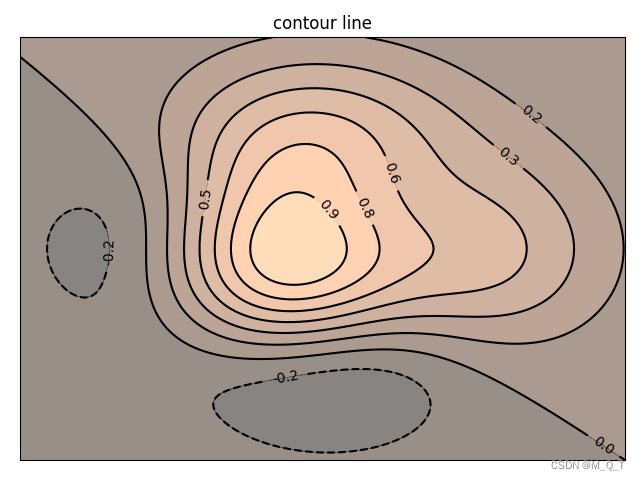
图31.4 等高线图示意概念的神经细胞存储,在新环境降低比对参数就可以招募到存有过往经历的细胞,作为生成当前策略的素材。
我们在第25节讲到,较大尺度的网格细胞与跟它们小几倍的网格联用,可以生成随机性,可能有助于新环境的探索。有些人把人生过成了目标任务清单(checklist),这对个人对社会都是一种遗憾,锁住了上限。
作为好奇的人类,我们的认知探索本质上也是追寻目标奖励的导航行为。这样的导航发生在一个更大的,更空旷的领域,伴随着更多的探索。如在一个随机游走中,行动方向可能偶尔改变,以在预期大小的奖励和潜在的更大潜在的奖励间的寻找平衡(图31.5)[24]。
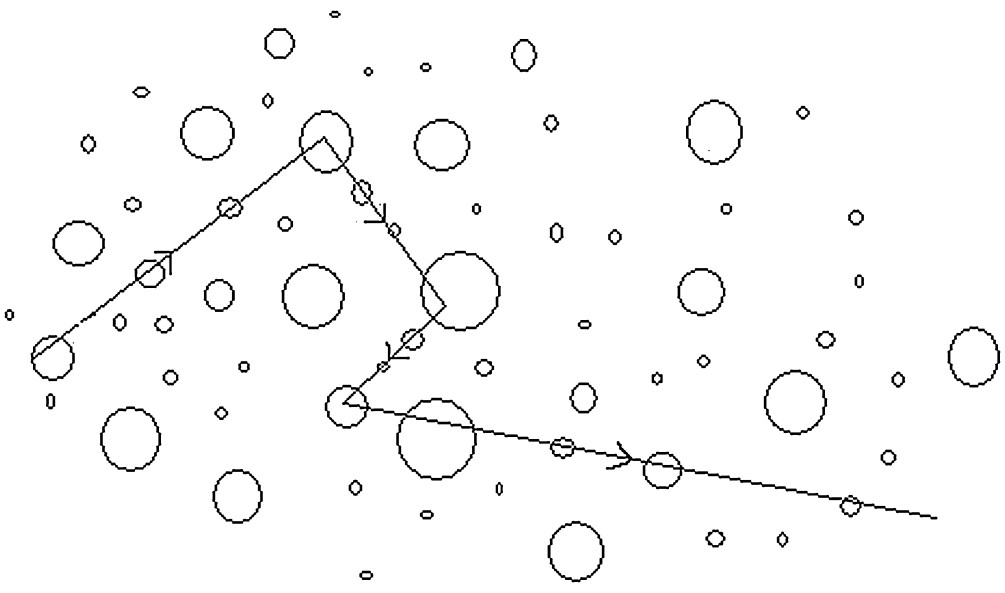
图31.5 Levy walk. 在包含圈状分布的资源上,μ = 2的levy游走运动模式的示意图。行进方向用箭头表示,初始行进方向是随机选择的。觅食者继续沿着同一方向移动,直到他们遇到一个圆圈 ,其质量由圆圈的大小表示,如新遇到的圈大于沿着这个方向移动时遇到的第一个遇到圈,则继续以该方向运动。否则随机选择一个新的旅行方向,循环往复。来自[25]
参考文献:
[1] Sharpe, Melissa J., Chun Yun Chang, Melissa A. Liu, Hannah M. Batchelor, Lauren E. Mueller, Joshua L. Jones, Yael Niv, and Geoffrey Schoenbaum. 2017. “Dopamine Transients Are Sufficient and Necessary for Acquisition of Model-Based Associations.” Nature Neuroscience 20 (5): 735–42. https://doi.org/10.1038/NN.4538.
[2] Wu, Chun-Ting, Daniel Haggerty, Caleb Kemere, and Daoyun Ji. 2017. “Hippocampal Awake Replay in Fear Memory Retrieval.” Nature Neuroscience 20 (4): 571–580.
[3] Tavares, Rita Morais, Avi Mendelsohn, Yael Grossman, Christian Hamilton Williams, Matthew Shapiro, Yaacov Trope, and Daniela Schiller. 2015. “A Map for Social Navigation in the Human Brain.” Neuron 87 (1): 231–243. https://doi.org/10.1016/j.neuron.2015.06.011.
[4] Sosa, Marielena, and Lisa M. Giocomo. 2021. “Navigating for Reward.” Nature Reviews Neuroscience 22 (8): 472–487. https://doi.org/10.1038/s41583-021-00479-z.
[5] Liu, Changliang, Pragya Goel, and Pascal S. Kaeser. 2021. “Spatial and Temporal Scales of Dopamine Transmission.” Nature Reviews Neuroscience 22 (6): 345–58. https://doi.org/10.1038/s41583-021-00455-7.
[6] Wang, Jane X., Zeb Kurth-Nelson, Dharshan Kumaran, Dhruva Tirumala, Hubert Soyer, Joel Z. Leibo, Demis Hassabis, and Matthew Botvinick. 2018. “Prefrontal Cortex as a Meta-Reinforcement Learning System.” Nature Neuroscience 21 (6): 860–868.
[7] Cai, X., Liu, C., Tsutsui-Kimura, I. et al. Dopamine dynamics are dispensable for movement but promote reward responses. Nature 635, 406–414 (2024). https://doi.org/10.1038/s41586-024-08038-z
[8] Aksoy-Aksel, Ayla, and Denise Manahan-Vaughan. 2013. “The Temporoammonic Input to the Hippocampal CA1 Region Displays Distinctly Different Synaptic Plasticity Compared to the Schaffer Collateral Input in Vivo: Significance for Synaptic Information Processing.” Frontiers in Synaptic Neuroscience 5: 5. https://doi.org/10.3389/fnsyn.2013.00005.
[9] Schapiro, Anna C., Nicholas B. Turk-Browne, Matthew M. Botvinick, and Kenneth A. Norman. 2017. “Complementary Learning Systems within the Hippocampus: A Neural Network Modelling Approach to Reconciling Episodic Memory with Statistical Learning.” Philosophical Transactions of the Royal Society B: Biological Sciences 372 (1711): 20160049. https://doi.org/10.1098/rstb.2016.0049.
[10] Singer, Annabelle C, and Loren M Frank. 2009. “Rewarded Outcomes Enhance Reactivation of Experience in the Hippocampus.” Neuron 64 (6): 910–921.
[11] Ólafsdóttir, H. F., Bush, D. & Barry, C. The role of hippocampal replay in memory and planning. Curr. Biol. 28, R37–R50 (2018).
[12] Stachenfeld, Kimberly L., Matthew M. Botvinick, and Samuel J. Gershman. 2017. “The Hippocampus as a Predictive Map.” Nature Neuroscience 20 (11): 1643–1653. https://doi.org/10.1038/NN.4650.
[13] Ambrose, R Ellen, Brad E Pfeiffer, and David J Foster. 2016. “Reverse Replay of Hippocampal Place Cells Is Uniquely Modulated by Changing Reward.” Neuron 91 (5): 1124–1136. https://doi.org/10.1016/j.neuron.2016.07.047.
[14] Wang, M., Foster, D. J. & Pfeiffer, B. E. Alternating sequences of future and past behavior encoded within hippocampal theta oscillations. Science 370, 247–250 (2020).
[15] Chantranupong, L., Beron, C.C., Zimmer, J.A. et al. Dopamine and glutamate regulate striatal acetylcholine in decision-making. Nature 621, 577–585 (2023). https://doi.org/10.1038/s41586-023-06492-9
[16] Warlow, S. M., Singhal, S. M., Hollon, N. G., Faget, L., Dowlat, D. S., Zell, V., Hunker, A. C., Zweifel, L. S., & Hnasko, T. S. (2023). Mesoaccumbal glutamate neurons drive reward via glutamate release but aversion via dopamine co-release. Neuron, 112(3), 488-499.e5.
[17] Tang, J.C.Y., Paixao, V., Carvalho, F. et al. Dynamic behaviour restructuring mediates dopamine-dependent credit assignment. Nature 626, 583–592 (2024). https://doi.org/10.1038/s41586-023-06941-5
[18] Zachry, J. E., Munir Gunes Kutlu, Hye Jean Yoon, Leonard, M. Z., Maxime Chevée, Patel, D. D., Gaidici, A., Kondev, V., Thibeault, K. C., Rishik Bethi, Tat, J., Melugin, P. R., Isiktas, A. U., Joffe, M. E., Cai, D. J., P. Jeffrey Conn, Grueter, B. A., & Calipari, E. S. (2024). D1 and D2 medium spiny neurons in the nucleus accumbens core have distinct and valence-independent roles in learning. Neuron, 112(5), 835-849.e7. https://doi.org/10.1016/j.neuron.2023.11.023
[19] Jovanoski, K.D., Duquenoy, L., Mitchell, J. et al. Dopaminergic systems create reward seeking despite adverse consequences. Nature 623, 356–365 (2023). https://doi.org/10.1038/s41586-023-06671-8
[20] Cazalé-Debat, L., Scheunemann, L., Day, M. et al. Mating proximity blinds threat perception. Nature 634, 635–643 (2024). https://doi.org/10.1038/s41586-024-07890-3
[21] Biswas, D., Lamperski, A., Yang, Y. et al. Mode switching in organisms for solving explore-versus-exploit problems. Nat Mach Intell 5, 1285–1296 (2023). https://doi.org/10.1038/s42256-023-00745-y
[22] Cheng, Sen, and Loren M Frank. 2008. “New Experiences Enhance Coordinated Neural Activity in the Hippocampus.” Neuron 57 (2): 303–13. https://doi.org/10.1016/j.neuron.2007.11.035.
[23] Foster, David J, and James J Knierim. 2012. “Sequence Learning and the Role of the Hippocampus in Rodent Navigation.” Current Opinion in Neurobiology 22 (2): 294–300. https://doi.org/10.1016/j.conb.2011.12.005.
[24] Liu, Y., Long, X., Martin, P.R. et al. Lévy walk dynamics explain gamma burst patterns in primate cerebral cortex. Commun Biol 4, 739 (2021). https://doi.org/10.1038/s42003-021-02256-1
[25] Reynolds, A. Liberating Lévy walk research from the shackles of optimal foraging. Phys. Life Rev. 14, 59–83 (2015).
[26] Liao Y, Wen R, Fu S, Cheng X, Ren S, Lu M, Qian L, Luo F, Wang Y, Xiao Q, Wang X, Ye H, Zhang X, Jiang C, Li X, Li S, Dang R, Liu Y, Kang J, Yao Z, Yan J, Xiong J, Wang Y, Wu S, Chen X, Li Y, Xia J, Hu Z, He C. Spatial memory requires hypocretins to elevate medial entorhinal gamma oscillations. Neuron. 2024 Jan 3;112(1):155-173.e8. doi: 10.1016/j.neuron.2023.10.012.

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}